
By Osman Aguirre, AI/ML engineer at Zazmic
In the early days of the AI boom, the goal was simple: “Make it work.” As 2026 unfolds, the mandate has shifted. Now, the goal is: “Make it scale without breaking the bank.”
When looking at AI architectures today, prompts and completions are only half the story. The real narrative is found in tokens—the literal currency of modern compute. If token overhead isn’t managed, an AI project isn’t a product; it’s a liability.
Why the Token Bill is Exploding
Most development cycles treat context windows like infinite RAM. They aren’t. They function more like metered bandwidth. In an Agentic Workflow, a single user query can trigger a chain reaction that burns through budgets:
- System Prompt: ~500 tokens.
- Tool Metadata: ~1,000 tokens.
- Recursive Reasoning: ~2,000+ tokens.
- Final Response: ~1,500 tokens.
A “simple” interaction can easily burn 5,000 tokens. Scaled to 200,000 users, that is a $15,000+ monthly bill for a single feature depending on model mix and pricing tier.
Cutting Token Bloat: What Actually Works
Efficiency requires pulling two primary levers: Unit Price (Model Selection) and Volume (Architecture).
1. Model Tiering (The “Right-Sizing” Strategy)
Using “Flagship” models for routing or formatting is an expensive mistake. High-performance architectures use a hierarchy:
- Reasoning Tier: GPT-5 or Claude 4.5 for complex logic.
- Execution Tier: Gemini 2.5 Flash for data extraction and summaries.
- Edge Tier: Gemini 2.5 Flash-Lite or local open-source models for basic classification.
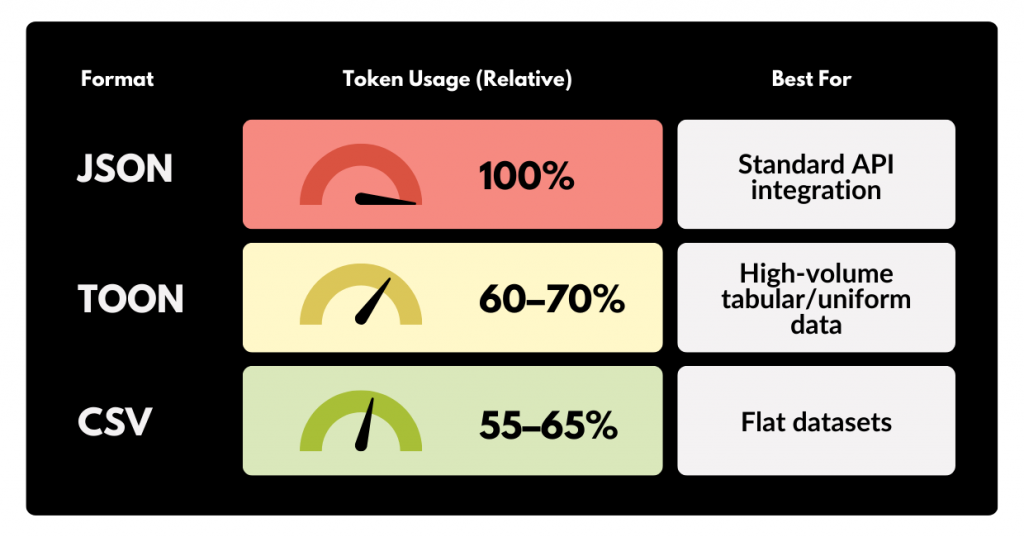
2. Serialization: TOON vs. JSON
JSON is the industry standard, but it is incredibly “noisy” for an LLM. Braces, quotes, and repeated keys cost real money.
TOON (Token-Oriented Object Notation) offers a cleaner path. By optimizing how data is structured for the model’s tokenizer, token counts can often be reduced by 30% to 60% without a loss in accuracy.
3. Visual Tokenization: Context as an Image
For long-form documents (PDFs, invoices, logs), moving away from text extraction is becoming the standard. By feeding an image of the document into a multimodal model, engineers can utilize “vision tokens.” In many cases, 100 vision tokens represent the same data as 1,000 text tokens—a 10x efficiency gain.
The Operational Checklist for Token-Sane AI
When reviewing an AI feature at Zazmic, these five optimizations are non-negotiable:
- Hard Context Caps: Payloads should be limited to 8–16 KB unless a specific exception is granted.
- Concise Defaults: Models should be forced to be brief. “Thinking out loud” is a debug flag, not a production default.
- Pre-Filtering: Instead of dumping a whole DB table into a prompt, vector search or SQL should prune the data first.
- Prompt Compression: Every word in a system prompt is an expense. If a rule doesn’t change the output, it should be deleted.
- FinOps Instrumentation: Dashboards must track tokens per user action. If a feature hits P95 cost limits, it goes back to the drawing board.
Efficiency is a Feature
The era of “AI at any cost” has ended. The most successful deployments in 2026 will be those that prioritize token hygiene from day one.
At Zazmic, the same rigor applied to cloud infrastructure is now applied to AI inference. Whether it’s implementing TOON or architecting multimodal pipelines, the goal is to build AI that is both powerful and economically sustainable.
Identify where the tokens are going. Join the next Zazmic workshop to audit prompts and architectural spend.