
Teams working with high-end GPUs rarely struggle to justify performance. What’s harder to justify is everything that happens between workloads.
For AI consultancies and R&D-heavy teams, compute usage tends to arrive in bursts. A model trains, an experiment runs, inference spins up for a client deliverable, and then the system waits. When the underlying hardware is an NVIDIA H100, that waiting time is often where most of the budget disappears.
This was the situation for Teldar, a Swiss AI consultancy delivering demanding machine learning workloads. Their projects required access to top-tier GPU performance, but not continuously. Leaving that infrastructure running as a precaution solved availability concerns while quietly creating a cost structure that didn’t match how the work was actually done.
When “Always Available” Stops Making Sense
Traditional cloud infrastructure assumes steady utilization. That assumption breaks down quickly once GPUs enter the picture.
With standard compute, idle time is tolerable. With H100-class instances, it becomes the dominant expense. Teams compensate in predictable ways:
- Keeping machines running to avoid setup delays
- Relying on manual provisioning during peak demand
- Accepting higher spend as an unavoidable cost of doing AI
Each of these approaches trades one problem for another. Over time, the side effects accumulate:
- Developers spend more time managing infrastructure
- Environments drift between runs
- Cost predictability deteriorates
What started as a convenience becomes an operational drag.
Teldar’s goal wasn’t simply to reduce spend. They wanted infrastructure that aligned with how their workloads actually behaved, rather than forcing their workflows to adapt to infrastructure constraints.
Designing Around Work, Not Capacity
We approached the problem with a simple constraint: a GPU instance should exist only while useful work is being done.
That led to a scale-to-zero architecture on Google Cloud, built around events rather than persistent capacity. Instead of keeping GPU instances alive “just in case,” the platform provisions resources in response to a workload and removes them immediately after execution completes.
To keep on-demand provisioning practical, the system uses pre-configured VM images and minimal boot-time initialization, keeping cold-start latency predictable rather than variable.
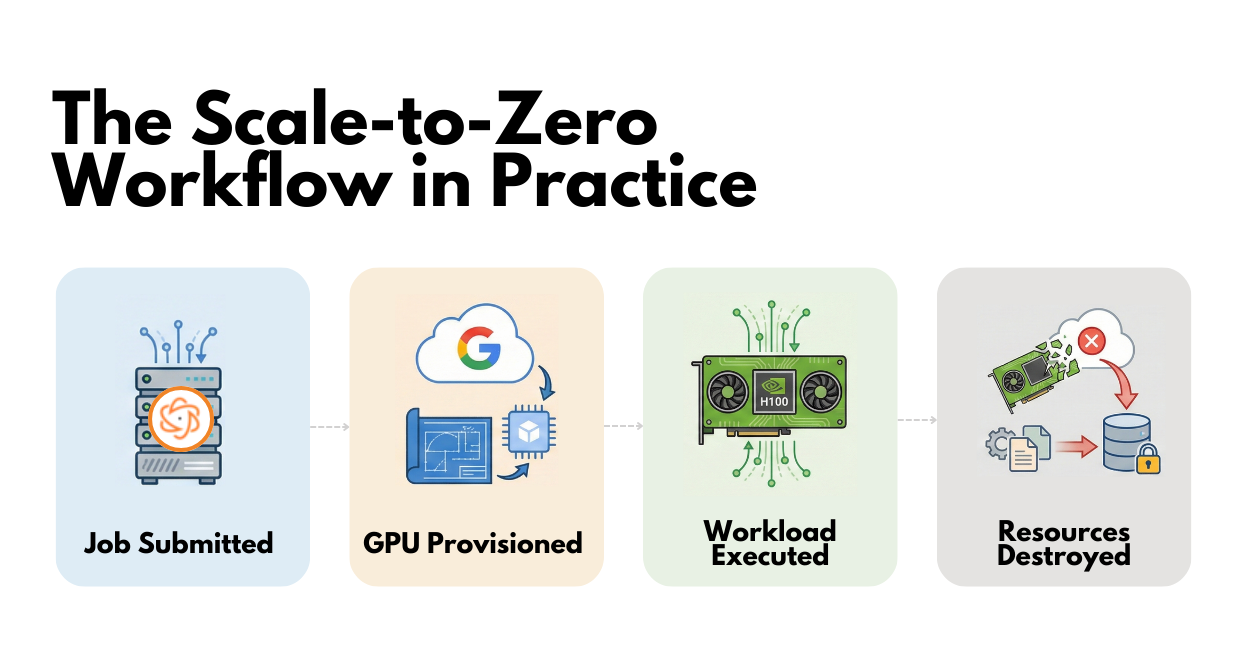
- A job is submitted
A training or inference task is triggered from Teldar’s existing pipeline, acting as the single signal that compute resources are required. - GPU infrastructure is provisioned automatically
In response to that event, the system creates a GPU-enabled virtual machine on Google Cloud using predefined infrastructure templates. No manual setup or pre-warmed instances are involved. - The workload runs
The job executes on dedicated NVIDIA H100 hardware in a clean, reproducible environment, with compute available for the full duration of the task. - All GPU resources are torn down on completion
As soon as the workload finishes, the system terminates the GPU instance and associated resources, ensuring no infrastructure remains running beyond the job’s lifetime. All model artifacts, checkpoints, and outputs are stored outside the compute layer in managed cloud storage, allowing jobs to be retried or repeated without relying on local state.
The goal wasn’t orchestration sophistication. It was predictability and removing humans from the infrastructure lifecycle entirely.
How the System Is Put Together
The platform relies on a small set of components, each with a clear role.
Compute
- Google Cloud A3 instances with NVIDIA H100 GPUs
- Provisioned as Spot Virtual Machines to reduce cost
Infrastructure Definition
- Terraform (Infrastructure as Code) defines all resources
- Ensures consistent, auditable environments across runs
Automation
- Google Cloud Functions manage provisioning and teardown
- Triggered by events from Teldar’s existing pipeline
From the ML team’s perspective, the process is largely invisible. They submit work and receive results; the infrastructure lifecycle handles itself.
Why Spot GPUs Fit This Model
Spot instances are often viewed as risky because they can be interrupted. That risk matters far less when infrastructure is designed to be ephemeral from the start.
In this model:
- Jobs can be retried without manual intervention
- Interruptions don’t create operational chaos
- Costs stay tightly coupled to actual execution time
For Teldar, this made access to H100-level performance economically viable without sacrificing reliability.
Operational Outcomes That Matter Long-Term
The most visible change was a significant reduction in GPU spend driven by the elimination of idle time. More important were the structural improvements that followed.
Day-to-Day Impact
- No manual provisioning delays
- No environment drift
- No need for engineers to act as infrastructure operators
Ownership and Autonomy
We delivered:
- Complete Infrastructure as Code artifacts
- Clear operational runbooks
- Documentation enabling independent operation
The platform was designed to be owned and extended by Teldar’s team, not continuously maintained by external engineers.
A Pattern AI Teams Should Reconsider
Many AI organizations still treat infrastructure as something to keep available “just in case.” That approach made sense when compute was inexpensive and workloads were predictable. It is far less defensible when the most powerful components in the system are also the most expensive.
Treating GPUs as ephemeral execution resources rather than long-lived assets changes both the economics and the engineering culture around them. Costs become easier to reason about, systems become simpler to operate, and teams regain time to focus on model development.
For teams running serious AI workloads, scale-to-zero is less about optimization and more about alignment—making infrastructure reflect how AI work actually happens, rather than how servers have traditionally been managed.